📋 목차
파이썬 리스트와 튜플은 겉보기에 비슷하지만 내부 구조부터 활용처까지 완전히 다르고, 이 차이를 제대로 이해하면 코드 성능과 안정성이 확 달라집니다.
솔직히 말하면 저도 처음 파이썬 배울 때 리스트랑 튜플 차이를 대수롭지 않게 봤거든요. “튜플은 변경 안 되는 리스트”라고만 외웠어요. 근데 실제로 프로젝트를 하다 보니 이게 단순한 문법 차이가 아니더라고요. 데이터 처리 속도가 눈에 띄게 달라지는 순간이 있었고, 딕셔너리 키로 좌표값을 넣어야 하는데 리스트로는 아예 불가능한 상황도 겪었습니다.
특히 한번은 수십만 건의 로그 데이터를 처리하면서, 전부 리스트로 담아뒀다가 메모리 사용량이 예상보다 훨씬 높게 나온 적이 있었어요. 그때 튜플로 바꾸기만 했는데 메모리가 눈에 띄게 줄어든 걸 보고 “아, 이게 진짜 차이구나” 체감했습니다. 그래서 오늘은 제가 직접 부딪히면서 알게 된 내용들을 정리해봤어요.
리스트와 튜플, 대체 뭐가 다른 건지
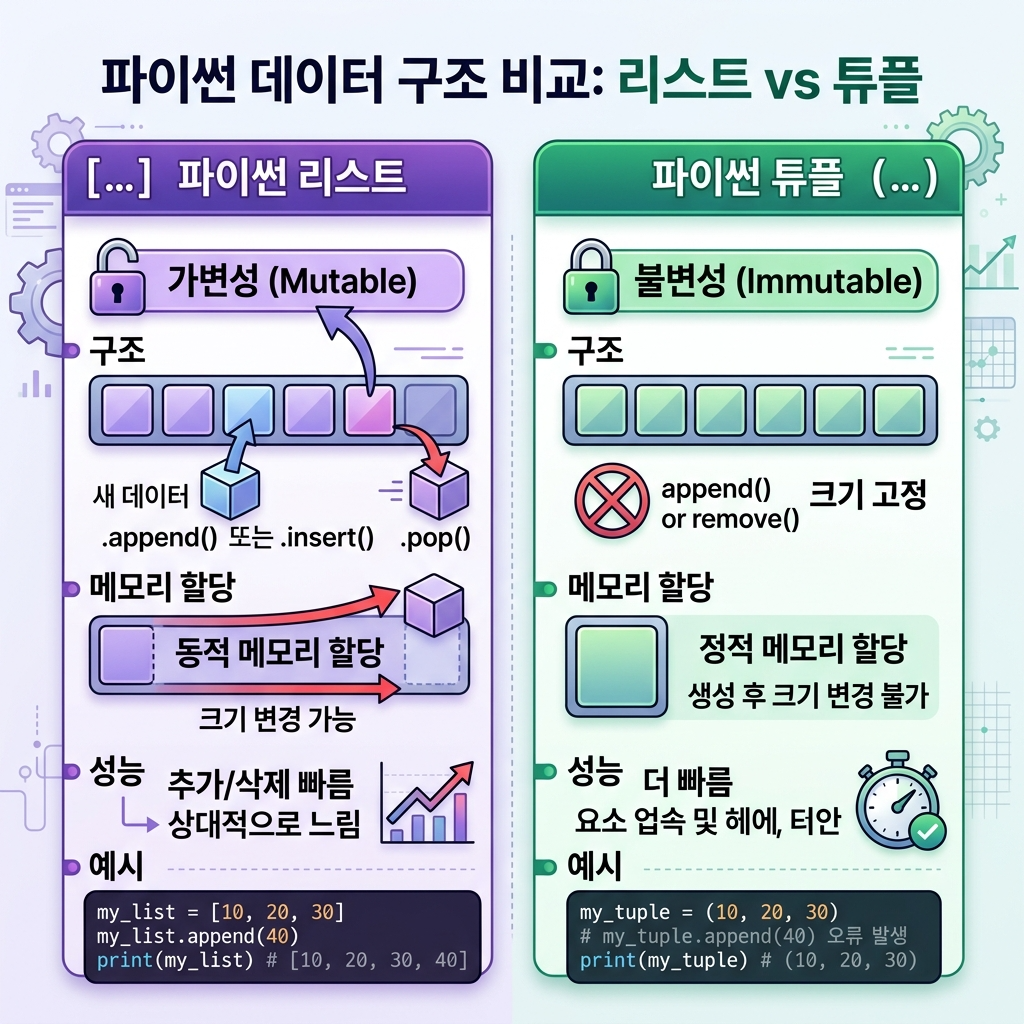
리스트는 대괄호 []로, 튜플은 소괄호 ()로 만든다는 건 대부분 아실 거예요. 근데 이 겉모습 차이가 내부적으로는 완전히 다른 메모리 구조를 만들어냅니다. 리스트는 동적 배열(dynamic array)이고, 튜플은 정적 배열(static array)이에요.
동적 배열이라는 건 데이터를 추가하거나 삭제할 수 있다는 뜻이거든요. 리스트에 append()를 쓰면 내부적으로 메모리를 재할당하는 resize 연산이 일어납니다. 이때 파이썬은 딱 필요한 만큼만 늘리는 게 아니라 여유분까지 포함해서 “초과 할당”을 해요. 나중에 또 추가할 거 대비해서요. 그래서 리스트는 항상 실제 데이터보다 좀 더 많은 메모리를 차지하고 있습니다.
반면 튜플은 한 번 만들면 끝이에요. 크기도 안 바뀌고 안의 값도 못 바꿔요. 그래서 초과 할당 같은 게 필요 없고, 구조 자체가 훨씬 단순합니다. CPython 소스코드를 보면, 리스트 객체는 ob_item 포인터 배열과 allocated 필드를 별도로 관리하는 반면, 튜플은 요소를 구조체 안에 직접 저장하거든요.
쉽게 비유하면 리스트는 늘었다 줄었다 하는 고무줄 가방이고, 튜플은 딱 맞는 하드케이스인 거예요. 각각 용도가 다릅니다.
변경 가능 vs 변경 불가, 이게 왜 중요한지
mutable(가변)과 immutable(불변). 파이썬의 자료형을 이해하려면 이 개념을 반드시 짚고 넘어가야 해요. 리스트는 mutable이라 생성 후에도 요소를 바꾸고, 추가하고, 삭제할 수 있습니다. 튜플은 immutable이라 한 번 만들면 절대 못 바꿔요.
근데 이게 왜 중요하냐면, 불변성이 보장되면 프로그램의 안정성이 올라가거든요. 제가 한번 팀 프로젝트에서 설정값들을 리스트로 관리했다가 낭패를 본 적이 있어요. 함수 A에서 설정 리스트를 받아서 처리하는데, 그 함수 내부에서 실수로 값을 하나 바꿔버린 거예요. 근데 같은 리스트 객체를 함수 B도 참조하고 있었으니까, B에서는 원래 값을 기대했는데 엉뚱한 값이 들어와 있던 겁니다. 디버깅하는 데 반나절 걸렸어요.
그 후로 변경될 필요가 없는 데이터는 무조건 튜플로 담기 시작했습니다. 실수로 수정하려고 하면 TypeError가 바로 뜨니까 버그를 사전에 막을 수 있거든요. DB에서 읽어온 레코드 한 줄, API 응답의 좌표값, 색상 코드 같은 건 전부 튜플이 맞아요.
💬 직접 써본 경험
Django ORM에서 쿼리 결과를 values_list()로 가져오면 기본이 튜플이에요. 처음에는 “왜 리스트로 안 주지?” 했는데, 수만 건의 데이터를 메모리에 올릴 때 튜플이 훨씬 가볍다는 걸 나중에야 이해했습니다. ORM 설계자가 괜히 그렇게 만든 게 아니더라고요.
다만 주의할 점이 있어요. 튜플 안에 리스트가 들어 있으면 그 리스트는 여전히 변경 가능합니다. t = ([1, 2], 3)이라고 했을 때 t[0].append(4)는 에러 없이 동작해요. 튜플의 불변성은 “튜플이 가리키는 참조가 바뀌지 않는다”는 의미이지, 참조 대상의 내용물까지 보호하지는 않거든요. 이거 모르면 나중에 꽤 헷갈립니다.
메모리와 속도 차이, 숫자로 확인해보니
“튜플이 가볍다”는 말, 대체 얼마나 차이 나는 걸까요? sys.getsizeof()로 직접 재보면 확 느껴집니다. 동일하게 요소 5개를 담았을 때 리스트는 104바이트, 튜플은 80바이트 정도가 나와요 (CPython 3.11, 64비트 기준). 요소가 늘어날수록 이 격차는 더 벌어지는데, 리스트는 초과 할당 때문에 실제 사용량보다 여유 메모리를 항상 잡아먹고 있기 때문이에요.
속도 차이도 무시할 수 없습니다. 벤치마크 결과를 보면 동일한 데이터로 리스트를 생성하는 데 약 37.9ns가 걸리는 반면, 튜플은 6.67ns밖에 안 걸린다는 측정 결과가 있어요. 거의 5~6배 차이인 거죠. 이 차이가 나는 핵심 이유가 있는데, 파이썬이 내부적으로 크기 20 이하의 튜플을 캐싱해두기 때문이에요.
| 비교 항목 | 리스트 (List) | 튜플 (Tuple) |
|---|---|---|
| 변경 가능 여부 | 가변 (mutable) | 불변 (immutable) |
| 메모리 (요소 5개) | 약 104바이트 | 약 80바이트 |
| 생성 속도 | 약 37.9ns | 약 6.67ns |
| 딕셔너리 키 사용 | 불가능 | 가능 (hashable) |
| 내부 캐싱 | 없음 | 크기 20 이하 캐싱 |
📊 실제 데이터
CPython 내부에서 크기 20 이하 튜플은 GC가 즉시 회수하지 않고 크기별로 최대 2만 개까지 캐싱해둡니다. 같은 크기의 튜플이 다시 필요하면 OS에 메모리를 새로 요청하지 않고 기존 메모리를 재활용하는 구조예요. 이게 생성 속도 차이의 핵심 원인입니다.
물론 요소를 조회하는 속도(인덱싱)는 리스트나 튜플이나 동일하게 O(1)이에요. 둘 다 연속 메모리에 저장되니까 인덱스로 바로 접근 가능합니다. 차이가 나는 건 생성과 메모리 점유 부분이지, 읽기 자체가 다른 건 아니에요. 이 부분을 혼동하시는 분이 꽤 많더라고요.
튜플만 가능한 것들 — 딕셔너리 키와 집합
튜플과 리스트의 진짜 결정적 차이가 여기서 나옵니다. 튜플은 hashable이에요. 해시값을 가질 수 있다는 뜻인데, 이 때문에 딕셔너리의 키(key)나 집합(set)의 요소로 사용할 수 있습니다. 리스트는 안 됩니다.
이게 실무에서 언제 필요하냐면, 예를 들어 지도 데이터를 다룰 때요. 위도와 경도 쌍을 딕셔너리의 키로 써야 하는 상황이 꽤 자주 옵니다. locations = {(37.5665, 126.9780): “서울시청”} 이런 식으로요. 이걸 리스트로 하면 TypeError가 뜹니다. “unhashable type: ‘list'”라는 메시지를 보게 되는 거죠.
저도 데이터 분석할 때 중복 좌표를 걸러내려고 set에 좌표를 넣었다가 리스트라서 실패한 경험이 있어요. 그때 튜플로 바꾸니까 바로 해결됐는데, 왜 hashable이어야 하는지 그제서야 와닿았습니다. 해시 테이블은 키의 해시값으로 데이터 위치를 결정하는데, 키가 바뀔 수 있으면 해시값도 바뀌니까 전체 테이블이 깨지는 거거든요. 그래서 불변 타입만 키로 쓸 수 있는 겁니다.
다만 아까 말한 것처럼, 튜플 안에 리스트가 포함되어 있으면 그 튜플도 hashable이 아니에요. ({1: 2},)처럼 딕셔너리를 품은 튜플도 마찬가지입니다. 불변 객체만으로 구성된 튜플이어야 hashable이 보장돼요.
상황별 선택 기준, 실무에서 이렇게 씁니다
결국 “언제 뭘 써야 하는데?”가 핵심이잖아요. 3년간 파이썬 쓰면서 제 나름의 기준이 생겼습니다.
리스트를 쓰는 건 데이터가 변할 때예요. 사용자 입력을 모으는 경우, 크롤링 결과를 하나씩 append 하는 경우, 필터링이나 정렬을 해야 하는 경우. 이런 상황에서는 당연히 리스트가 맞습니다. append()의 시간 복잡도가 평균 O(1)이니까 데이터를 계속 추가하는 작업에는 리스트가 압도적으로 유리해요.
튜플을 쓰는 건 데이터가 고정일 때입니다. 함수에서 여러 값을 동시에 return 할 때 파이썬이 자동으로 튜플을 만들어주잖아요. RGB 색상값 (255, 128, 0), DB 레코드 한 행, 설정 상수 모음 같은 거요. 딕셔너리 키로 복합 키가 필요하면 튜플 말고는 선택지가 없고요.
제가 실수했던 건 “성능 때문에 무조건 튜플”이라고 생각했던 시기가 있었다는 거예요. 근데 데이터를 합쳐야 하는 상황에서 튜플의 + 연산은 매번 새 객체를 만들어서 O(n)이 걸립니다. 리스트의 append()가 평균 O(1)인 것과 비교하면 엄청난 차이죠. 1만 건의 데이터를 하나씩 합치는 작업을 튜플로 했다가 리스트 대비 수십 배 느렸던 기억이 있어요. 용도에 맞는 선택이 제일 중요합니다.
💡 꿀팁
함수가 여러 값을 반환할 때 return a, b, c라고 쓰면 자동으로 튜플 (a, b, c)가 됩니다. 받는 쪽에서 x, y, z = func()로 언패킹하면 되는데, 이 패턴은 파이썬에서 가장 자연스러운 튜플 활용법이에요. 변수 스왑도 a, b = b, a 한 줄이면 끝나는데, 이것도 내부적으로는 튜플 패킹·언패킹입니다.
흔한 오해와 실수 바로잡기
첫 번째로 많이들 착각하는 게 “튜플은 읽기 전용 리스트”라는 거예요. 기능적으로 보면 맞는 말 같지만, 의미론적으로는 좀 다릅니다. 리스트는 “같은 성격의 데이터 여러 개”를 담는 데 적합하고, 튜플은 “서로 다른 성격의 데이터를 하나로 묶는 레코드”에 가까워요. (name, age, email) 같은 구조가 전형적인 튜플의 쓰임새인 거죠.
두 번째 오해. “요소 하나짜리 튜플”을 만들 때 실수하는 경우가 정말 많아요. t = (1)이라고 쓰면 이건 그냥 정수 1이에요. 괄호가 연산 우선순위용으로 해석되거든요. 요소 하나짜리 튜플은 t = (1,)처럼 콤마를 꼭 찍어야 합니다. 저도 이거 때문에 type()을 찍어보고 “왜 int지?” 하면서 한참 헤맸던 적이 있어요.
세 번째, 튜플이 항상 리스트보다 빠른 건 아닙니다. 아까 말했듯이 데이터를 반복적으로 합치는 작업에서는 리스트가 훨씬 빨라요. 그리고 리스트 컴프리헨션은 for문 + append()보다 실행 속도가 빠릅니다. 상황마다 최적의 도구가 다른 거예요.
⚠️ 주의
튜플 안에 가변 객체(리스트, 딕셔너리 등)가 포함되면 그 내부는 변경 가능합니다. t = ([1, 2], 3)에서 t[0].append(4)는 정상 동작하지만, t[0] = [5]는 TypeError가 뜹니다. 참조 자체는 못 바꾸지만 참조 대상의 내용은 바꿀 수 있다는 점, 놓치면 예상 못한 버그로 이어집니다.
마지막으로 하나 더. 파이썬의 named tuple을 알면 튜플 활용도가 확 올라갑니다. collections.namedtuple이나 typing.NamedTuple을 쓰면 튜플의 각 요소에 이름을 붙일 수 있어서, 인덱스 번호 대신 point.x, point.y 같은 식으로 접근할 수 있거든요. 가독성과 불변성을 동시에 잡는 좋은 방법이에요.
결국 리스트와 튜플은 “뭐가 더 좋다”가 아니라 “언제 뭘 쓸 것인가”의 문제입니다. 변할 데이터면 리스트, 안 변할 데이터면 튜플. 딕셔너리 키가 필요하면 튜플. 대량 데이터를 메모리 절약하면서 읽기만 할 거면 튜플. 이 기준만 기억하면 대부분의 상황에서 올바른 선택을 할 수 있어요.
❓ 자주 묻는 질문
Q. 리스트를 튜플로, 튜플을 리스트로 변환할 수 있나요?
네, tuple()과 list() 함수로 간단히 변환 가능합니다. 다만 변환할 때마다 새 객체가 생성되므로 대량의 데이터를 반복 변환하면 성능에 영향이 있어요. 필요한 시점에 한 번만 변환하는 게 좋습니다.
Q. 튜플도 정렬할 수 있나요?
sorted() 함수를 쓰면 되지만, 결과는 리스트로 반환됩니다. 튜플 자체에는 sort() 메서드가 없어요. 정렬된 결과를 다시 튜플로 쓰고 싶으면 tuple(sorted(t))로 감싸면 됩니다.
Q. 빈 튜플은 어떻게 만드나요?
t = () 또는 t = tuple()로 만들 수 있어요. 빈 튜플은 CPython에서 싱글톤으로 관리되기 때문에 아무리 많이 만들어도 메모리상 같은 객체를 가리킵니다. id()로 확인해보면 주소가 동일하게 나와요.
Q. namedtuple과 dataclass 중 뭘 써야 하나요?
불변 레코드가 필요하면 namedtuple이 가볍고 좋습니다. 메서드를 추가하거나 기본값 설정, 타입 힌트가 필요하면 dataclass(frozen=True)가 더 유연해요. 단순 데이터 묶음이냐 객체 지향이냐로 판단하면 됩니다.
Q. 리스트 안에 튜플, 튜플 안에 리스트를 넣어도 되나요?
문법적으로는 전혀 문제없습니다. 다만 튜플 안에 리스트를 넣으면 그 튜플은 hashable이 아니게 되어 딕셔너리 키나 set 요소로 사용할 수 없어요. 용도에 따라 의도적으로 구성하되, 해시 가능 여부를 꼭 확인하세요.
본 포스팅은 개인 경험과 공개 자료를 바탕으로 작성되었으며, 전문적인 의료·법률·재무 조언을 대체하지 않습니다. 정확한 정보는 해당 분야 전문가 또는 공식 기관에 확인하시기 바랍니다.
리스트는 변하는 데이터의 유연한 그릇이고, 튜플은 변하지 않는 데이터의 안전한 금고입니다. 데이터가 추가·삭제되는 상황이라면 리스트를, 한 번 정해지면 바뀌지 않는 값이라면 튜플을 선택하세요. 딕셔너리 키나 set 요소가 필요한 경우에는 튜플이 유일한 선택지고요.
이 글이 리스트와 튜플 선택에 도움이 됐다면 댓글로 여러분의 활용법도 공유해주세요. 공유 버튼 한 번이면 파이썬 입문자 동료에게도 큰 도움이 됩니다.