📋 목차
파이썬으로 특정 폴더 안의 파일 목록을 한 번에 가져오고 싶은데, os.listdir·os.scandir·os.walk 중 뭘 써야 할지 헷갈리셨다면 — 제가 직접 속도 비교까지 해본 결과를 공유합니다.
솔직히 말하면, 처음에 저도 os.listdir 하나만 알았거든요. 데이터 분석 프로젝트 하면서 폴더 안에 CSV 파일 2천 개를 정리해야 하는 상황이었는데, 그냥 listdir로 돌렸다가 원하는 파일만 골라내는 데 코드가 쓸데없이 길어졌어요. 그때 scandir이랑 walk을 알게 됐고, 특히 대용량 폴더에서 속도 차이가 꽤 크다는 걸 체감했습니다.
근데 단순히 “이 함수가 빠르다”로 끝나는 게 아니거든요. 상황마다 맞는 함수가 다르고, pathlib이라는 모던한 대안도 있어서 한 번에 정리해두면 두고두고 써먹을 수 있어요. 파이썬 입문하신 분부터, 실무에서 파일 자동화 스크립트 짜는 분까지 읽어보시면 시간 아낄 수 있을 거예요.
폴더 파일 리스트, 왜 자꾸 삽질하게 되는 걸까
파일 리스트 가져오기. 말만 들으면 엄청 쉬워 보이잖아요. import os 하고 os.listdir 한 줄이면 끝일 것 같은데, 실제로 해보면 생각보다 변수가 많아요.
일단 “파일만” 가져오고 싶은데 폴더(디렉토리)까지 같이 나옵니다. 그러면 os.path.isfile로 일일이 걸러야 하거든요. 여기서 벌써 한 번 꼬이기 시작해요. 게다가 하위 폴더 안의 파일까지 포함하고 싶으면 listdir만으로는 안 되고, 재귀 로직을 직접 짜거나 os.walk를 써야 합니다.
제가 처음 헤맸던 이유가 정확히 이거였어요. “폴더 안 파일 가져오기”라는 하나의 작업인데, 상황에 따라 쓰는 함수가 전부 달라요. 한 단계 폴더만 볼 건지, 깊이 있게 들어갈 건지, 파일 속성(크기, 수정일)까지 필요한지에 따라 최적의 선택이 바뀌거든요.
파이썬 공식 문서에서도 Python 3.5 이후로는 os.scandir을 권장하고 있고, 더 최근 흐름은 pathlib 모듈 쪽으로 넘어가는 추세예요. 근데 여전히 레거시 코드나 빠른 스크립트에서는 listdir이 압도적으로 많이 쓰이고요. 그래서 전부 알아둬야 합니다.
os.listdir 기본기부터 확실하게 잡기
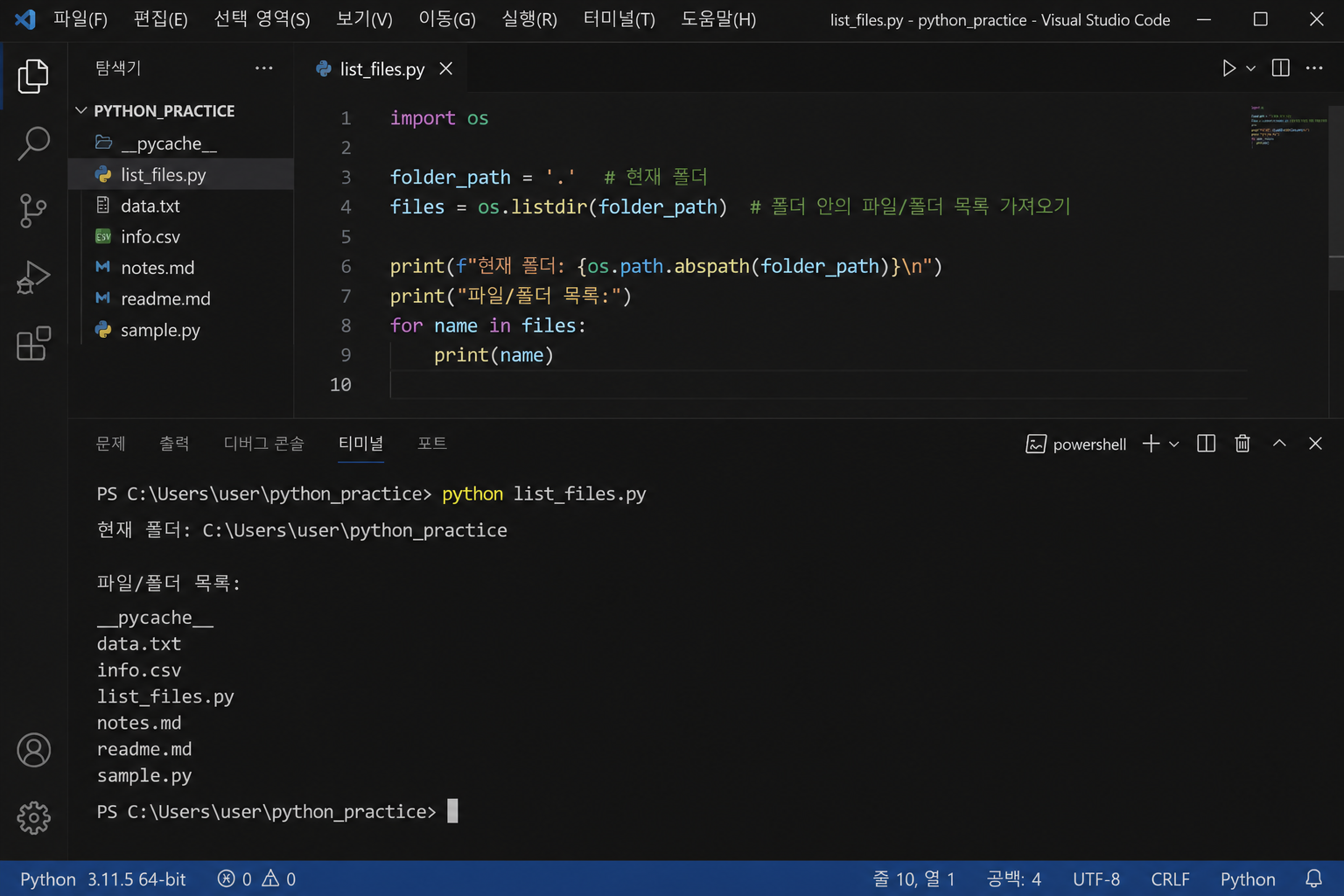
가장 기본이 되는 함수부터 가볼게요. os.listdir(경로)를 호출하면, 해당 경로 안에 있는 파일과 폴더의 이름을 리스트로 돌려줍니다. 말 그대로 이름만요. 경로 정보도 안 붙어 있어요.
예를 들어 이런 식이에요. import os 하고 file_list = os.listdir(‘./data’) 하면, [‘report.csv’, ‘image.png’, ‘backup’] 이런 식으로 나와요. 여기서 backup이 폴더인지 파일인지는 이 결과만 봐서는 알 수가 없거든요. 파일만 걸러내려면 os.path.isfile(os.path.join(‘./data’, f))처럼 경로를 합쳐서 하나씩 체크해야 합니다.
근데 이 과정에서 문제가 하나 있어요. os.path.isfile을 호출할 때마다 운영체제한테 stat() 시스템 콜을 보냅니다. 파일이 100개면 100번, 1만 개면 1만 번이에요. 소규모 폴더에서는 체감이 안 되는데, 파일이 수천 개 넘어가면 눈에 띄게 느려져요.
그래서 단순히 “이 폴더에 뭐가 있나” 이름만 빠르게 확인할 때는 listdir이 여전히 가장 심플합니다. 근데 파일인지 폴더인지 구분해야 하거나, 파일 크기·수정일까지 알아야 하는 상황이라면 다른 방법이 훨씬 효율적이에요.
💡 꿀팁
os.listdir에 경로를 안 넣으면 현재 작업 디렉토리(os.getcwd() 결과)를 기준으로 동작해요. 근데 이게 스크립트 실행 위치에 따라 달라지기 때문에, 항상 절대 경로나 명시적 상대 경로를 넣어주는 게 안전합니다. 저도 초반에 이것 때문에 “분명 파일이 있는데 빈 리스트가 나온다”고 한참 고민했던 적 있거든요.
os.scandir으로 바꿨더니 체감 속도가 달라진 이유
Python 3.5에서 추가된 os.scandir은, 솔직히 listdir의 상위 호환이라고 봐도 무방해요. PEP 471 문서를 보면 이 함수가 왜 만들어졌는지 이유가 명확한데, 핵심은 불필요한 시스템 콜 제거입니다.
운영체제가 디렉토리를 읽을 때(readdir on POSIX, FindNextFile on Windows), 사실 파일 이름뿐만 아니라 “이게 파일인지 디렉토리인지” 같은 부가 정보도 같이 넘겨주거든요. 근데 os.listdir은 이 정보를 버리고 이름만 반환해요. 그래서 나중에 isfile이나 isdir을 또 호출하면 OS한테 같은 질문을 두 번 하는 셈이에요.
os.scandir은 이 낭비를 없앴어요. DirEntry 객체를 반환하는데, 여기에 name, path는 물론이고 is_file(), is_dir(), stat() 메서드가 붙어 있어서 추가 시스템 콜 없이 바로 확인할 수 있습니다. 특히 Windows에서는 stat 정보까지 캐싱되기 때문에 대규모 디렉토리에서 2~5배, PEP 471 벤치마크 기준으로는 최대 20배까지 빨라진 사례도 있어요.
코드도 오히려 깔끔해져요. with os.scandir(‘./data’) as entries: 로 시작해서, for entry in entries: 돌리면서 entry.is_file()로 바로 필터링하면 끝이거든요. 저는 CSV 파일 2천 개짜리 폴더에서 listdir + isfile 조합을 scandir으로 바꿨을 때, 체감상 확실히 빨라졌고 코드 줄 수도 줄었어요.
📊 실제 데이터
PEP 471 공식 벤치마크에 따르면, os.scandir 기반으로 개선된 os.walk는 Windows에서 약 8~9배, POSIX 시스템(Linux/macOS)에서 약 2~3배 빨라졌습니다. 시스템 콜 횟수가 2N에서 N으로 줄어든 결과예요. 파일 수가 많을수록 이 차이는 더 벌어집니다.
하위 폴더까지 싹 긁어오는 os.walk 재귀 탐색
os.listdir이나 os.scandir은 해당 폴더 한 단계만 봐요. 근데 실무에서는 하위 폴더 안에 또 하위 폴더가 있고, 그 안에 파일이 흩어져 있는 경우가 훨씬 많잖아요. 이럴 때 os.walk가 진가를 발휘합니다.
os.walk(경로)를 호출하면 제너레이터가 반환되는데, for 문으로 돌릴 때마다 (현재 디렉토리 경로, 하위 디렉토리 리스트, 파일 리스트) 이렇게 세 값을 튜플로 줍니다. 알아서 재귀적으로 모든 하위 폴더를 타고 내려가요. 제가 직접 재귀 함수를 짤 필요가 없다는 게 포인트예요.
실제로 제가 프로젝트 정리할 때 이런 식으로 썼어요. for root, dirs, files in os.walk(‘./project’): 돌리면서 files 안에서 .py로 끝나는 것만 골라서 전체 경로(os.path.join(root, f))를 리스트에 담았거든요. 폴더 구조가 3단계 깊이였는데 코드 다섯 줄이면 전부 긁어와요.
한 가지 주의할 건, os.walk는 기본적으로 심볼릭 링크를 따라가지 않아요. 순환 참조 때문에 무한 루프에 빠질 수 있거든요. followlinks=True 옵션이 있긴 한데, 정말 필요한 경우가 아니면 기본값 그대로 두는 게 안전합니다. 저도 한 번 followlinks=True로 네트워크 드라이브 탐색했다가 스크립트가 안 끝나서 강제 종료한 적 있어요.
참고로 Python 3.5 이후부터 os.walk 내부도 scandir 기반으로 동작합니다. 예전 버전에서는 listdir + isdir 조합이라 느렸는데, 지금은 자동으로 최적화된 상태예요.
listdir vs scandir vs walk vs pathlib 실전 비교
자, 이쯤 되면 “그래서 뭘 쓰라는 거냐”는 질문이 나올 수밖에 없잖아요. 상황별로 달라서 표 하나로 정리했습니다.
| 항목 | os.listdir | os.scandir |
|---|---|---|
| 반환 형태 | 문자열 리스트 | DirEntry 이터레이터 |
| 파일/폴더 구분 | 별도 stat 필요 | is_file() 내장 |
| 하위 폴더 탐색 | 불가(직접 재귀) | 불가(직접 재귀) |
| 대용량 속도 | 느림 | 2~20배 빠름 |
| 추천 상황 | 이름만 빠르게 | 속성 확인 필요 시 |
os.walk는 위 두 함수와 목적 자체가 달라요. 하위 폴더를 재귀적으로 탐색하는 게 핵심이니까, “깊이 들어가야 하면 walk, 현재 폴더만 보면 scandir”이라고 외우면 됩니다.
그리고 요즘 트렌드는 pathlib인데요. from pathlib import Path 해서 Path(‘./data’).iterdir()로 현재 폴더를 순회하거나, Path(‘./data’).glob(‘*.csv’)로 패턴 매칭을 할 수 있어요. 반환값이 Path 객체라 경로 조합이나 확장자 추출이 훨씬 직관적이에요. 다만 pathlib의 is_file()이나 stat()은 캐싱을 안 하기 때문에 호출할 때마다 시스템 콜이 나간다는 차이가 있어요. 대용량 폴더에서 성능이 중요하다면 os.scandir이 여전히 유리합니다.
제 기준으로는 이렇게 골라요. 빠른 스크립트에서 이름만 확인 — listdir. 파일 속성까지 빠르게 — scandir. 하위 폴더 전체 탐색 — walk. 코드 가독성 우선 — pathlib. 어떤 걸 쓰든 틀린 건 아닌데, 상황에 안 맞는 걸 쓰면 코드가 불필요하게 복잡해지거나 느려집니다.
확장자별 필터링과 실무에서 자주 쓰는 패턴
파일 리스트를 가져오는 건 사실 중간 단계잖아요. 대부분은 “특정 확장자만 골라내기”가 진짜 목적이에요. CSV만 모은다거나, 이미지 파일만 따로 처리한다거나.
가장 흔한 방법은 리스트 컴프리헨션이에요. [f for f in os.listdir(path) if f.endswith(‘.csv’)] 이 한 줄이면 CSV만 쏙 빠져나와요. 여러 확장자를 동시에 걸러야 할 때는 endswith에 튜플을 넣으면 됩니다. f.endswith((‘.jpg’, ‘.png’, ‘.gif’)) 이렇게요.
근데 이보다 더 편한 게 glob 모듈이에요. import glob 하고 glob.glob(‘./data/*.csv’) 치면 해당 폴더에서 CSV만 전체 경로 포함해서 리스트로 줍니다. 하위 폴더까지 재귀 탐색하고 싶으면 glob.glob(‘./data/**/*.csv’, recursive=True)로 ** 패턴을 쓰면 돼요. pathlib에서도 Path(‘./data’).rglob(‘*.csv’)로 똑같이 할 수 있고요.
제가 실무에서 제일 많이 쓰는 패턴은 이거예요. scandir로 순회하면서 entry.name.endswith(‘.xlsx’)와 entry.is_file()을 동시에 체크하는 방식. glob보다 세밀한 조건(파일 크기, 수정일 등)을 한 번에 걸 수 있어서 자동화 스크립트에서는 이게 가장 실용적이더라고요.
💬 직접 써본 경험
회사에서 매주 월요일마다 특정 폴더에 쌓이는 Excel 리포트를 자동으로 합치는 스크립트를 만들었는데, 처음에 glob으로 *.xlsx를 잡았더니 임시 파일(~$report.xlsx)까지 같이 잡혀서 에러가 났어요. 결국 scandir + 조건 필터링으로 바꾸고, entry.name.startswith(‘~$’)인 것을 제외하는 로직을 추가했습니다. 이런 예외 처리가 필요한 실무에서는 glob만으로는 부족할 때가 있어요.
처음에 몰라서 헤맸던 실수 3가지
첫 번째, 경로 구분자 문제예요. 윈도우에서는 백슬래시(\)를 쓰는데, 파이썬 문자열 안에서 백슬래시는 이스케이프 문자거든요. ‘C:\new_folder’ 이렇게 쓰면 \n이 줄바꿈으로 인식돼요. raw string(r’C:\new_folder’)을 쓰거나 슬래시(‘C:/new_folder’)로 통일하면 해결됩니다. 저는 이거 때문에 “경로가 존재하지 않습니다” 에러를 한참 봤어요.
두 번째, os.scandir의 컨텍스트 매니저 미사용이에요. scandir은 OS 리소스를 잡고 있기 때문에 with 문으로 감싸주는 게 권장돼요. with os.scandir(path) as it: 이렇게 쓰면 블록이 끝날 때 자동으로 리소스가 해제됩니다. 안 감싸도 당장은 동작하지만, 대량 반복 시 리소스 누수가 생길 수 있어요.
세 번째는 의외로 많은 분이 놓치는 건데, 한글 폴더명 인코딩 문제예요. os.listdir에 바이트 경로를 넣으면 바이트 문자열이 반환되고, 문자열 경로를 넣으면 유니코드 문자열이 반환돼요. 한글 폴더명이 포함된 환경에서는 반드시 문자열(str) 경로를 사용해야 깨지지 않아요. 파이썬 공식 문서에서도 str 타입 경로 사용을 강력 권장하고 있습니다.
⚠️ 주의
os.scandir이 반환하는 DirEntry 객체는 “쓰고 버리는” 용도로 설계됐어요. 이터레이션이 끝난 뒤에 DirEntry를 변수에 저장해두고 나중에 stat()을 다시 호출하면, 캐시된 오래된 정보가 나올 수 있습니다. 파일 변경 감시 같은 용도에는 pathlib.Path나 os.stat()을 직접 호출하는 게 맞아요.
이 세 가지만 알아도 os 모듈 관련 에러의 절반은 사전에 막을 수 있어요. 흔한 오해 중 하나가 “os.walk가 느리다”는 건데, Python 3.5 이후 버전에서는 내부적으로 scandir을 쓰기 때문에 예전처럼 느리지 않아요. 구버전 파이썬에서의 경험이 그대로 전해져 내려온 거라, 최신 환경에서는 walk도 충분히 빠릅니다.
자주 묻는 질문
Q. os.listdir은 정렬된 순서로 결과를 반환하나요?
아니요. 운영체제가 넘겨주는 순서 그대로 반환하기 때문에 알파벳 순이 아닐 수 있어요. 정렬이 필요하면 sorted(os.listdir(path))로 감싸주면 됩니다.
Q. 숨김 파일(.으로 시작하는 파일)도 리스트에 포함되나요?
네, 포함돼요. 단, ‘.’과 ‘..’ (현재 디렉토리, 상위 디렉토리)는 listdir과 scandir 모두 자동으로 제외합니다. .gitignore 같은 점(.)으로 시작하는 일반 파일은 나옵니다.
Q. pathlib과 os 모듈을 섞어 쓰면 문제가 되나요?
기능상 문제는 없어요. Path 객체를 str()로 감싸면 os 모듈 함수에 그대로 넣을 수 있고, os.fspath()로 변환도 가능합니다. 다만 코드 일관성을 위해 한 프로젝트 안에서는 하나로 통일하는 게 읽기 편해요.
Q. 파일 개수가 10만 개 이상인 폴더에서 가장 빠른 방법은?
os.scandir이 가장 유리합니다. 이터레이터 방식이라 메모리에 전체 리스트를 올리지 않고, DirEntry의 캐싱 덕분에 추가 시스템 콜도 최소화돼요. listdir은 전체를 리스트로 한 번에 메모리에 올리기 때문에 메모리 효율도 scandir이 앞서요.
Q. glob.glob과 Path.glob의 결과가 다를 수 있나요?
패턴 매칭 규칙 자체는 동일하지만, 반환 타입이 달라요. glob.glob은 문자열 경로를, Path.glob은 Path 객체를 반환합니다. 기능적 차이보다는 이후 코드에서 경로를 어떻게 다룰지에 따라 선택하면 됩니다.
본 포스팅은 개인 경험과 공개 자료를 바탕으로 작성되었으며, 전문적인 의료·법률·재무 조언을 대체하지 않습니다. 정확한 정보는 해당 분야 전문가 또는 공식 기관에 확인하시기 바랍니다.
정리하면, 이름만 빠르게 확인할 때는 os.listdir, 파일 속성까지 빠르게 가져와야 할 때는 os.scandir, 하위 폴더 전체를 탐색해야 할 때는 os.walk, 코드 가독성을 높이고 싶을 때는 pathlib을 쓰면 됩니다. 대용량 폴더에서 성능까지 챙기고 싶다면 scandir을 기본으로 가져가는 게 가장 실용적이에요.
혹시 파일 자동화 스크립트 만들면서 겪은 에피소드가 있으시면 댓글로 공유해 주세요. 비슷한 상황에서 도움이 되는 분이 분명 계실 거예요. 유용하셨다면 공유도 부탁드립니다.